








この投稿文は次の言語で読めます:
![]() 日本語
日本語
Contents
概要
MT4/MT5にはファイル出力関数があり、それによってインジケーターの値等を外部ファイルに出力できます。
出力ファイルをそのまま分析ツールのインプットとして利用することもありますが、場合によっては分析ツール側で
扱いやすいような形式にデータを集計、加工した状態のデータを分析ツールのインプットとした方が
集計仕様が単純になり、分析ツール側で無理な実装を避けることが出来、結果として作業負荷減に繋がります。
いわゆるデータ準備工程の話ですが、
zigzagベースのカスタムインジケーターから出力した値を元に傾向分析をした際にも、この準備工程が必要でしたので
そのファイルを集計・加工する手順に関する紹介です。
※MT5とPythonスクリプトを連携して起動するものではなく、自動化前の検証工程における情報整理です。
環境
言語はPython、ツールはJetBrains PyCharmと Jupyter Notebookを使用します。
Python
機械学習等でもよく利用されるスクリプト言語のため、データ取得や、集計、加工等のクレンジングに役立つライブラリも豊富に揃っています。
パッケージ等の環境整備も、Anaconda Navigator を使用することで案件毎に適用するパッケージやバージョンを管理できます。
Jupyter Notebook
pythonの実行コマンドを対話形式で実行可能にしてくれるツールのため、
1ステップずつ実行結果を確認しながら開発、修正を繰り返していく作業にとても適しています。
スクリプトを一通り全部書いてからデバッグしていると、どこで何の問題があったのか切り分ける時間が必要になりますが、
その無駄な時間を無くしてくれる、とても素晴らしいツールです。
PyCharm + Jupyter Notebook
PyCharmには、 Jupyter Notebookへの接続手順が標準で備わっています。
※詳細はこちらを参照。
基本的な操作感はブラウザ上で動作する本家と大きく変わらず違和感なく使えますが、PyCharm利用が圧倒的にオススメです。
それは、IntelliJと同じIDEのため、従来利用していたホットキーや各種エディタ設定(ダークテーマ、フォントとか)が共通的に利用できることや、
ソースコードの入力補完、機械学習向けライブラリのヘルプ参照等、作業効率の面で有利な点が多数あります。
手順
pandas というデータ分析用ライブラリを使います。
ファイル読取結果を二次元配列的に柔軟に扱えるDataFrame型で返してくれるのが魅力です。
ファイル読取
import pandas as pd file = "[directory_path]/zigzag_USDJPY_H1.csv" df = pd.read_csv(file)<実行結果>

エラーでコケます。。
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xff in position 0: invalid start byteutf-8、ポジション0 でffなので、BOMでしょうか?
エンコード指定でファイルを開くため、 codecsも import してやり直し。
import pandas as pd
import codecs
file = "[directory_path]/zigzag_USDJPY_H1.csv"
file_prep = "[directory_path]/prep_zigzag_USDJPY_H1.csv"with codecs.open(file, 'r', 'UTF-16') as r:
with codecs.open(file_prep, 'w', 'UTF-8') as w:
for line in r:
w.write(line)df = pd.read_csv(file_prep) df.head()<実行結果>

BOMが原因でした。 無事に読み取れました。
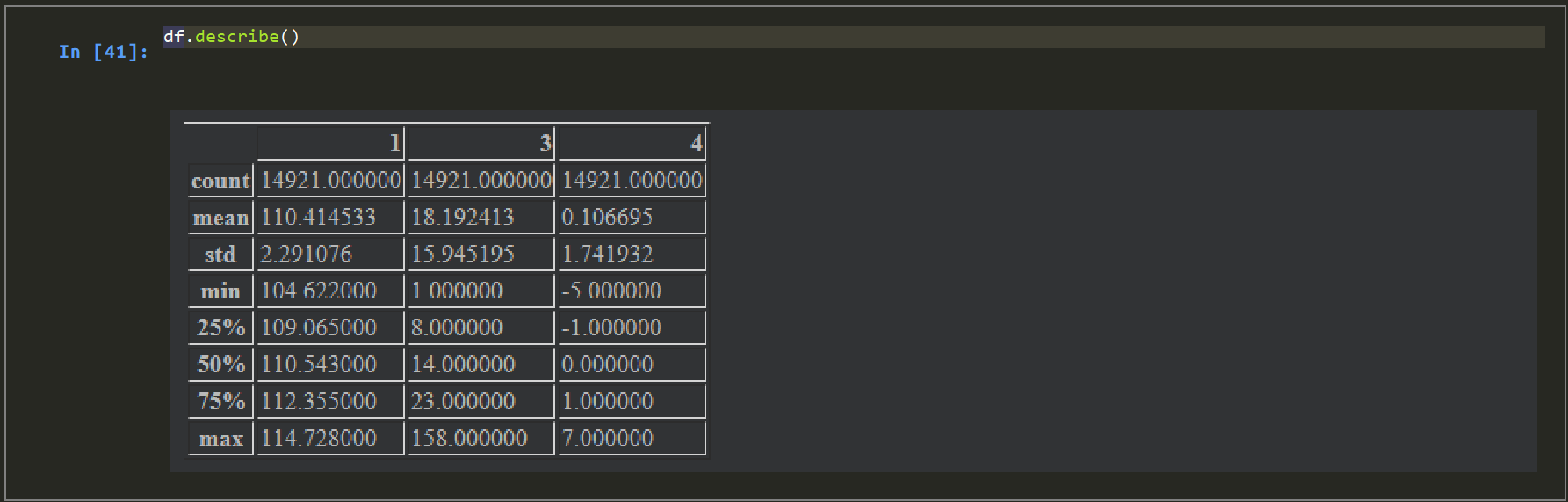
念のため、取得件数くらいを確認しておきます。
# DataFrame内のcount がファイル内レコード件数と一致していればOK。
df.describe()<実行結果>
# 別の手段でファイル内行数を確認 num_lines = sum(1 for line in open(file_prep)) num_lines<実行結果>問題なさそうです。

ヘッダを付与
# 一行目がヘッダになってしまっているので、ヘッダなしで読取り。
#df = pd.read_csv(file_prep)
#↓
df = pd.read_csv(file_prep, header=None)
df.head()<実行結果>
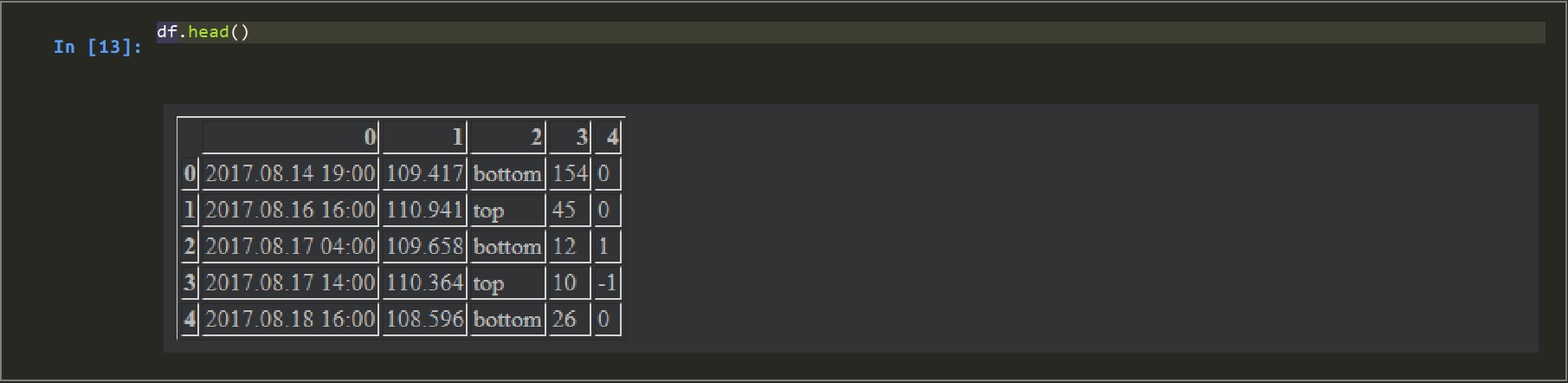
ヘッダが認識されました。
# 列名を変更します。
df = df.rename(columns={0:'check_date',1:'rate',2:'category',3:'bar_count',4:'count'})
df.head()
<実行結果>
前列以前の値を横方向に展開(SQLのLAG/LEAD関数的な操作)
# 特定の列のみを取り出す(SQLの列指定のようなもの。射影。)
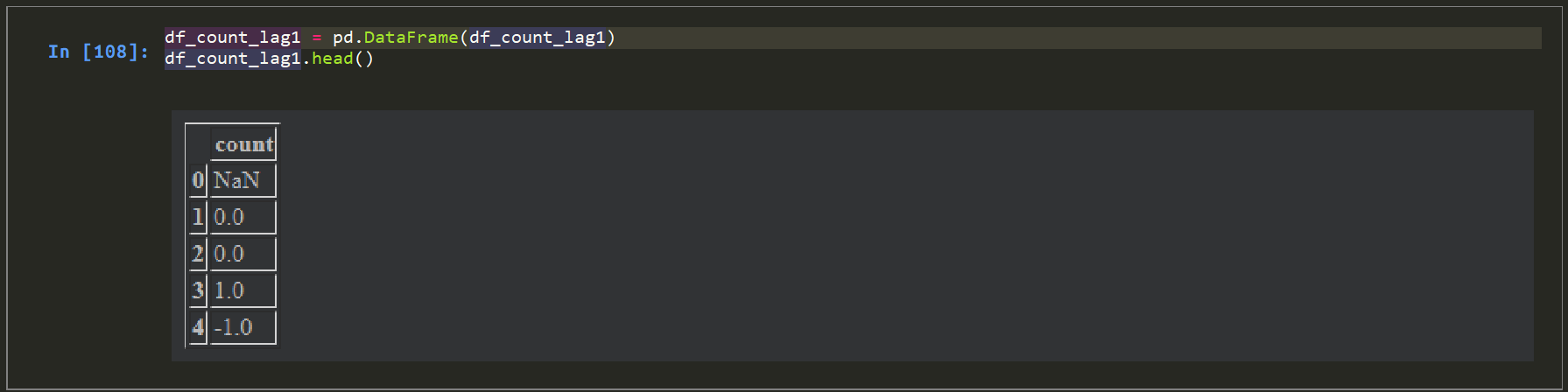
df['count']# 一行分ずらす。 df_count_lag1 = df['count'].shift(1)<実行結果>

# 取得結果が pandas.Series になっているので、DataFrameへ変換。
df_count_lag1 = pd.DataFrame(df_count_lag1)
df_count_pre1.head()
<実行結果>
#カラム名修正。
df_count_pre1 =df_count_pre1.rename(columns={'count':'count_pre1'})
df_count_pre1.head()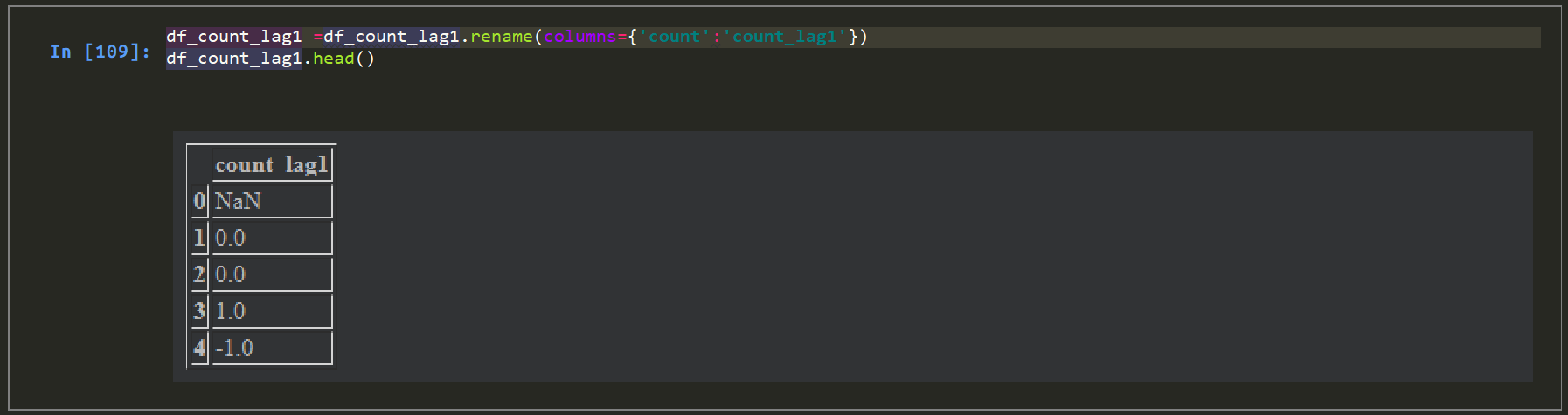
正しく取れました。
# 残りも同様に列を生成します。
df_count_lag2 = pd.DataFrame(df['count'].shift(2)).rename(columns={'count':'count_lag2'})
df_count_lag3 = pd.DataFrame(df['count'].shift(3)).rename(columns={'count':'count_lag3'})
df_count_lag4 = pd.DataFrame(df['count'].shift(4)).rename(columns={'count':'count_lag4'})
df_count_lag5 = pd.DataFrame(df['count'].shift(5)).rename(columns={'count':'count_lag5'})# 元のデータソースと結合します。
df_prep = pd.concat([df, df_count_lag1, df_count_lag2, df_count_lag3, df_count_lag4, df_count_lag5], axis=1)
df_prep.head(10)<実行結果>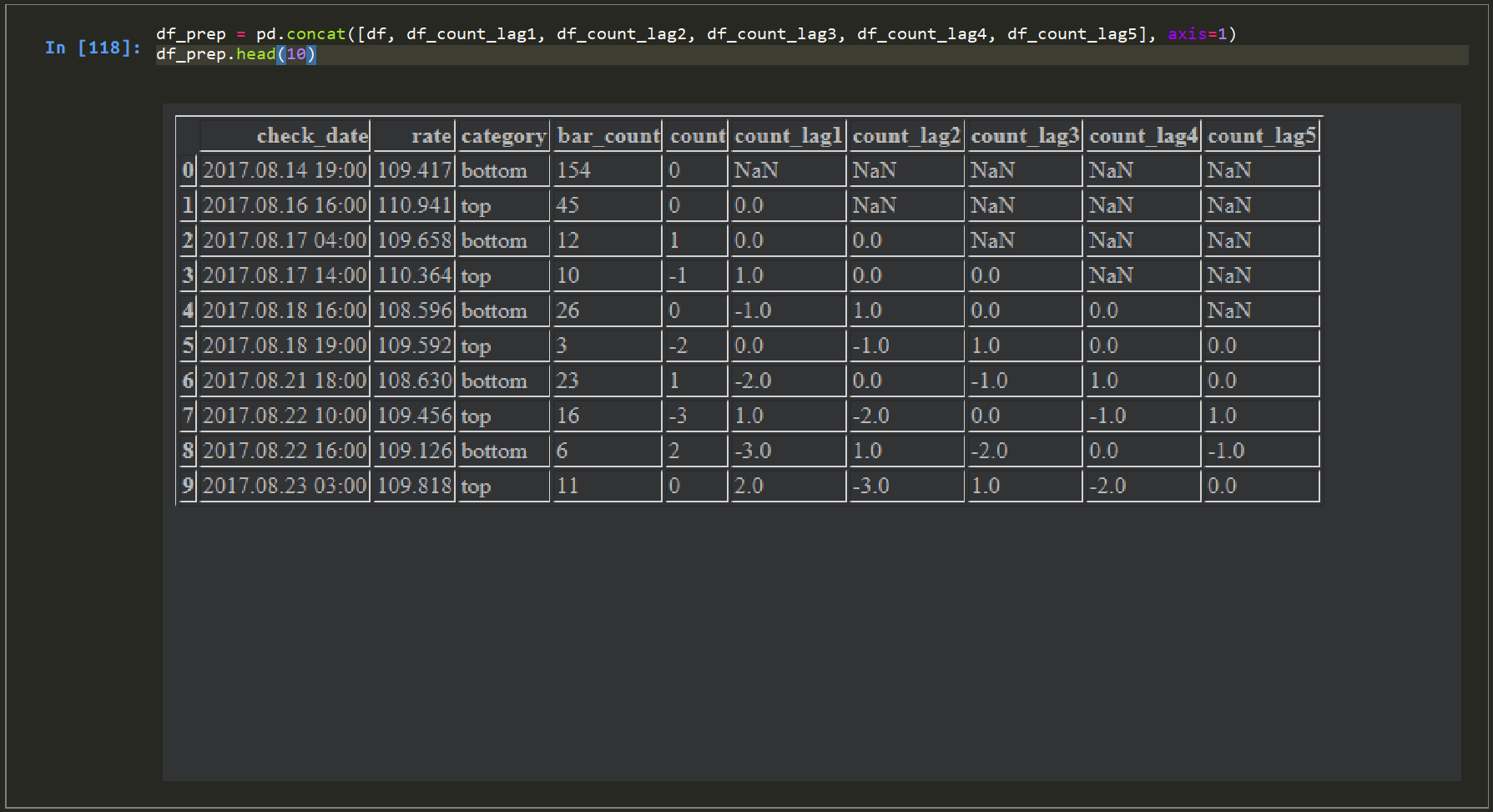
ファイル出力
df_prep.to_csv('[directory_path]/output_zigzag_USDJPY_H1_12_5_3.csv')これでファイルが出力されました。
出来上がったファイルは分析ツールのインプットとして活用したり、そのまま引き続きpython上で集計し指標化しても問題ありません。
まとめ
若干手順が長くなりましたが、上記のようにトライ&エラーして出来上がったものを
.py形式にして出力、微調整すれば、そのままバッチ処理としても利用ができるようになります。
検証用データを作りながら自動化の手順を整理していると思えば、Excelでこねくり回しているよりも遥かに生産的ですね。














